The following is an illustration accompanying an article published on Microsoft, an independent research firm focused exclusively on Microsoft strategy & technology.
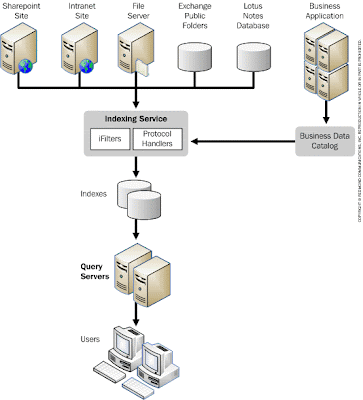
Enterprise search in SharePoint Server 2007 depends on two main components. An indexing service on a central server crawls enterprise data resources and builds full-text indexes to speed search. Query servers allow users to conduct searches. (In small-scale deployments, the indexing and query server can be combined on a single machine.)
Out of the box, the SharePoint Server 2007 indexing service reads data from more than 200 types of sources, including SharePoint sites, HTML pages on other types of intranet sites, files on file servers, Exchange Public Folders, and Lotus Notes databases. The service can be extended to index more data types by installing additional iFilters, which are usually written by third-party ISVs or partners. A separate technology known as protocol handlers lets the indexing service retrieve data over different types of connections, such as the Hypertext Transfer Protocol (HTTP) or the File Transfer Protocol (FTP). The Business Data Catalog service, available in the full version of SharePoint Server 2007, integrates data from business applications (e.g., an ERP application) into SharePoint Server 2007, allowing the indexing service to index data from these applications without requiring custom iFilters or protocol handlers.
In SharePoint Server 2007, indexes created by the indexing service propagate continuously to query servers, even while the indexing service is rebuilding indexes with new information. Users conduct queries against the indexes on the query servers through the Web-based Search Center user interface, or a search Web Part.
For most situations, Microsoft recommends that organizations have only one server running the indexing service, because indexing requires significant computing resources both on the indexing machine and the machines being crawled. However, farms of servers can host multiple indexing services, each of which can crawl a different but overlapping set of resources; each query server can then be limited to a particular index (not shown in the illustration). Microsoft recommends this only in situations where security or regulation requires strict segregation between divisions of an organization—for example, between stock analysts and investment bankers

Enterprise search in SharePoint Server 2007 depends on two main components. An indexing service on a central server crawls enterprise data resources and builds full-text indexes to speed search. Query servers allow users to conduct searches. (In small-scale deployments, the indexing and query server can be combined on a single machine.)
Out of the box, the SharePoint Server 2007 indexing service reads data from more than 200 types of sources, including SharePoint sites, HTML pages on other types of intranet sites, files on file servers, Exchange Public Folders, and Lotus Notes databases. The service can be extended to index more data types by installing additional iFilters, which are usually written by third-party ISVs or partners. A separate technology known as protocol handlers lets the indexing service retrieve data over different types of connections, such as the Hypertext Transfer Protocol (HTTP) or the File Transfer Protocol (FTP). The Business Data Catalog service, available in the full version of SharePoint Server 2007, integrates data from business applications (e.g., an ERP application) into SharePoint Server 2007, allowing the indexing service to index data from these applications without requiring custom iFilters or protocol handlers.
In SharePoint Server 2007, indexes created by the indexing service propagate continuously to query servers, even while the indexing service is rebuilding indexes with new information. Users conduct queries against the indexes on the query servers through the Web-based Search Center user interface, or a search Web Part.
For most situations, Microsoft recommends that organizations have only one server running the indexing service, because indexing requires significant computing resources both on the indexing machine and the machines being crawled. However, farms of servers can host multiple indexing services, each of which can crawl a different but overlapping set of resources; each query server can then be limited to a particular index (not shown in the illustration). Microsoft recommends this only in situations where security or regulation requires strict segregation between divisions of an organization—for example, between stock analysts and investment bankers
Comments
Post a Comment